在人工智能领域取得又一突破性进展的9月12日,OpenAI官方隆重推出了其最新力作——模型o1。这款模型的最大亮点在于,它融合了强化学习(RL)的训练方法,并在模型推理过程中采用了更为深入的内部思维链(chain of thought,简称CoT)技术。这一创新性的结合,使得o1在物理、化学、数学等需要强大逻辑推理能力的学科领域内,实现了性能的显著提升。
OpenAI的这一成果,无疑为人工智能领域树立了新的标杆。RL+CoT的范式,不仅在效果上显著增强了模型的强逻辑推理能力,更为后续国内外大模型厂商的研发方向提供了新的思路。可以预见,在未来的日子里,沿着RL+CoT这一新路线,各大厂商将持续迭代模型,推动人工智能技术迈向新的高度。
重心由预训练转移到后训练和推理
2020年,OpenAI提出的Scaling Law为大模型的迭代奠定了重要的理论基础。在o1模型发布之前,Scaling Law主要聚焦于预训练阶段,通过增加模型的参数数量、扩大训练数据集以及提升算力,来增强模型的智能表现。然而,随着o1模型的推出,OpenAI揭示了在预训练Scaling Law的基础上,通过在后训练阶段引入强化学习(RL)并在推理过程中增加长内部思维链(CoT,意味着更多的计算步骤),同样能够显著提升模型的性能。这表明,Scaling Law不仅适用于预训练阶段,还能在大模型的后训练和推理阶段持续发挥作用。
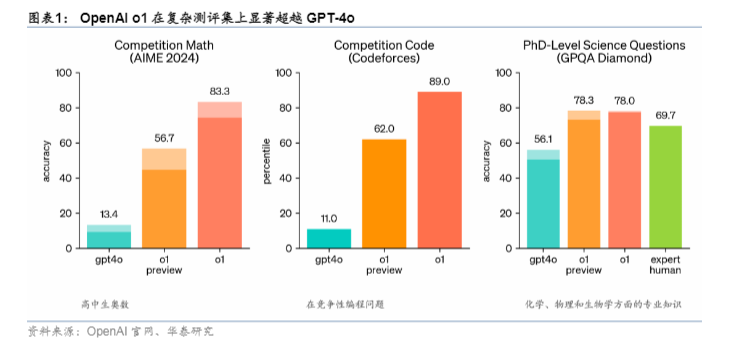
具体来说,o1模型在编程、数学和科学领域的能力都得到了大幅提升。在Codeforces编程竞赛中,o1模型的表现超过了83%的专业人员;在数学竞赛方面,以AIME 2024为例,GPT-4o平均只能解决12%的问题,而o1模型平均能解决74%的问题,若采用64个样本的共识,解决率更是能达到83%;在科学能力方面,对于博士级的科学问题(GPQA Diamond),GPT-4o的精确度为56.1%,人类专家水平为69.7%,而o1模型则达到了78%,超越了人类专家的能力。
o1模型的问世,为下一步大模型的训练和迭代提供了新的参考范式——即RL+CoT。从定性角度看,RL+CoT需要更多的训练和推理算力。在o1模型之前,如GPT-4o等模型主要经历了预训练和后训练(基于人类反馈的强化学习RLHF)两个阶段,推理则采用单次推理或短CoT。然而,o1模型在预训练阶段的算力变化可能并不大,主要目的是保证模型具有较好的通用能力。在后训练阶段,由于采用了RL,模型需要通过不断搜索的方式来迭代优化输出结果,因此算力消耗有望上升。在推理阶段,o1模型在RL训练下学会了内部长CoT,推理所需的token数量明显增长,因此推理算力相比之前的单次推理或短CoT也显著上升。

综上所述,在新的大模型训练范式下,从定性角度看,模型需要更多的训练和推理算力来支持其性能的提升。
算力和应用端或值得关注
目前升级版的AI大模型主要聚焦于强化逻辑推理能力,通过实现完整的分步骤推理过程,可以显著提升回复的逻辑性和条理性。这一升级预示着Agent Network的初步框架即将形成,对于那些需要更严密逻辑处理的B端用户,有望率先从中受益。同时,随着系统对复杂实际环境中边缘场景的处理能力得到增强,其应用范围和效果也将得到进一步提升。
华泰证券分析指出,RL+CoT的训练范式不仅延续了预训练阶段的Scaling Law,还进一步将其扩展到了后训练和推理阶段。在预训练算力保持相对稳定的情况下,RL后训练和CoT推理将催生新的算力需求。这些需求的具体规模将取决于RL搜索的深度、CoT的内在长度以及推理效果之间的平衡。由于RL+CoT实际上为行业内的其他模型开发商设定了下一代模型迭代的基本框架,预计这一范式将被广泛采纳,从而带动训练算力需求的显著提升。在此背景下,建议投资者关注与算力相关的企业,如博通、沪电股份、工业富联等。
此外,尽管o1模型目前主要解决的是数学、代码和科学领域的推理问题,但其核心在于构建模型的CoT能力。CoT作为推理的重要手段,有望在端侧结合用户的更多私有数据进行应用。苹果AI Agent被视为实现CoT能力的理想计算平台。因此,建议投资者关注与苹果产业链相关的企业,包括立讯精密、鹏鼎控股、水晶光电、歌尔股份、蓝思科技、东山精密、长电科技等。
最后,o1模型展现出的强逻辑推理能力有望扩展到更广泛和通用的领域,并且在推理性能上相较于前代模型有显著提升。这意味着基于o1及后续大模型的AI应用和Agent有望在能力上实现本质性的超越。因此,建议投资者关注核心的AI应用企业,如微软、奥多比、金山办公、泛微网络、萤石网络等。

